宽变压器型号的功率
本文是我们对最新AI 研究报道的一部分。
Transformer 是近年来最具影响力的机器学习架构之一。它是一些最先进的深度学习系统的基础,包括 OpenAI 的GPT-3和 DeepMind 的 AlphaFold 等大型语言模型。
Transformer 架构的成功归功于其强大的注意力机制,这使其能够超越其前身RNN和 LSTM。Transformer 模型可以并行处理正向和反向的长数据序列。
鉴于变压器网络的重要性,有几项努力来提高其准确性和效率。其中一项举措是剑桥大学、牛津大学和伦敦帝国理工学院的科学家开展的一项新研究项目,该项目建议将变压器架构从深向宽转变。虽然是一个小的架构变化,但结果表明,这种修改显着提高了变压器网络的速度、内存和可解释性。
改进变压器架构
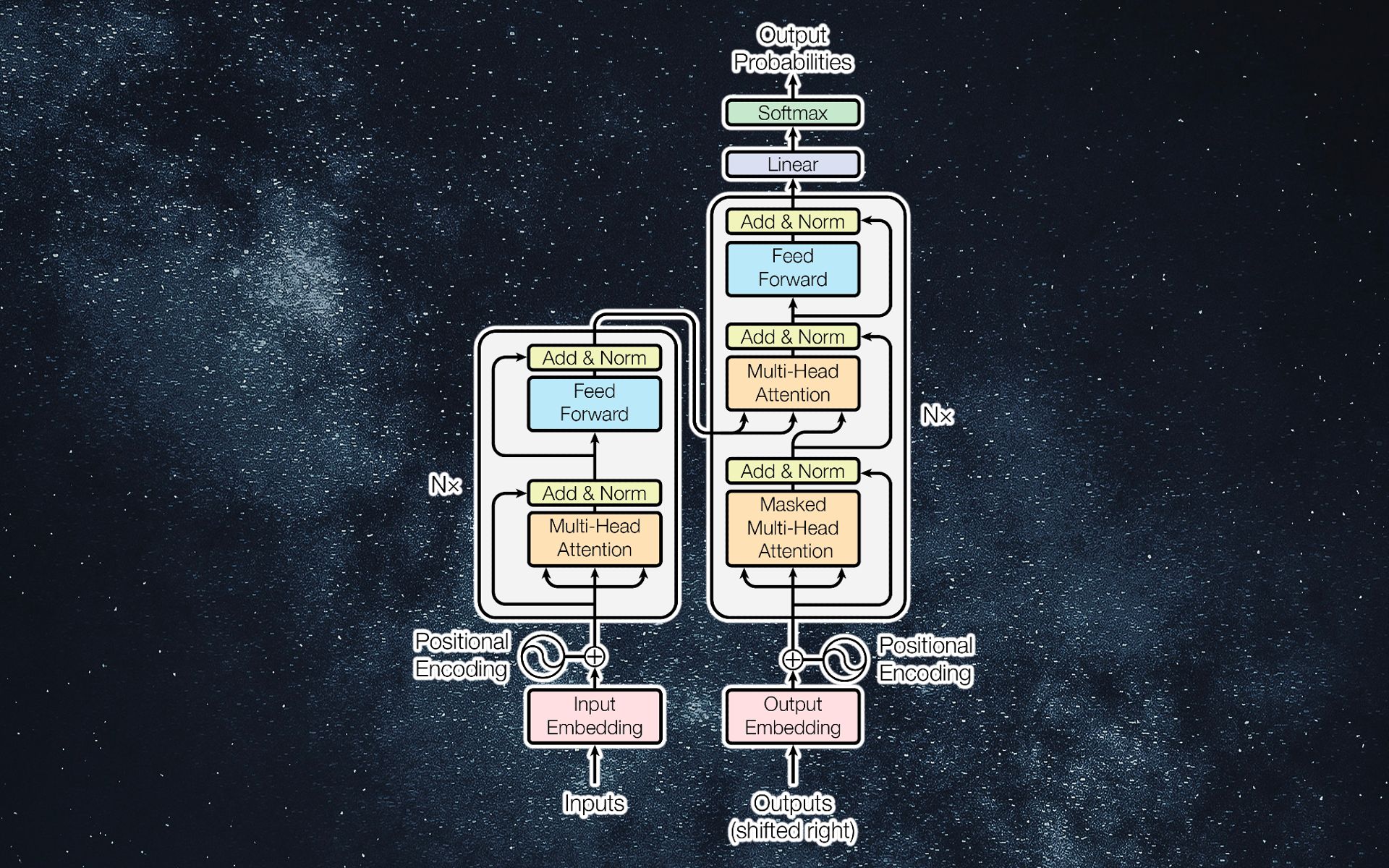
2017 年推出的原始 Transformer 架构由使用类似组件的编码器和解码器模块组成。后来又引入了其他的transformer变体,其中一些只使用了编码器或解码器部分。例如,BERT 是一个仅编码器的变压器模型,而 GPT-3 是一个仅解码器的网络。
考虑一个仅编码器的转换器模型,它将电影或产品的评论分类为正面或负面。输入文本首先被转换为具有位置编码的嵌入。嵌入是单词的多维数字表示。因此,一串文本变成了一个多维向量数组。位置编码修改嵌入值以说明序列中每个单词的位置。
这些值被馈送到注意层,这是变压器的主要构建块。注意层由几个注意头组成。在训练阶段,每个注意力头配置其参数以捕获不同输入之间的关系。然后可以将输出展平并馈送到一个或多个全连接层,最后变成二进制分类输出。
以前改进转换器的尝试主要集中在创建专门针对特定任务的新注意力机制。剑桥大学、牛津大学和伦敦帝国理工学院的科学家们提出了一个想法,与其改变注意力机制,不如重新思考变压器的总体架构?结果是一种新技术,可以提高转换器的性能,同时也不受任务和注意力机制的影响。
“我们最初是在研究不同的注意力机制,以及是否可以结合不同的注意力来提高性能,”该论文的合著者、剑桥大学工程系学生 Jason Brown 告诉TechTalks。
研究人员创建了一个单层转换器模型,该模型结合了许多不同的注意力头作为他们搜索实验的一部分。令他们惊讶的是,他们发现该模型尽管整体尺寸较小,但性能出乎意料地好。
“探索这背后的原因,我们发现这是因为它在注意力中具有相同的总计算量,而只有一层,”布朗说。“由于变形金刚的训练和运行成本非常高,因此能够在保持准确性的同时提高它们的效率是一个令人兴奋的前景。”
深与宽变压器模型
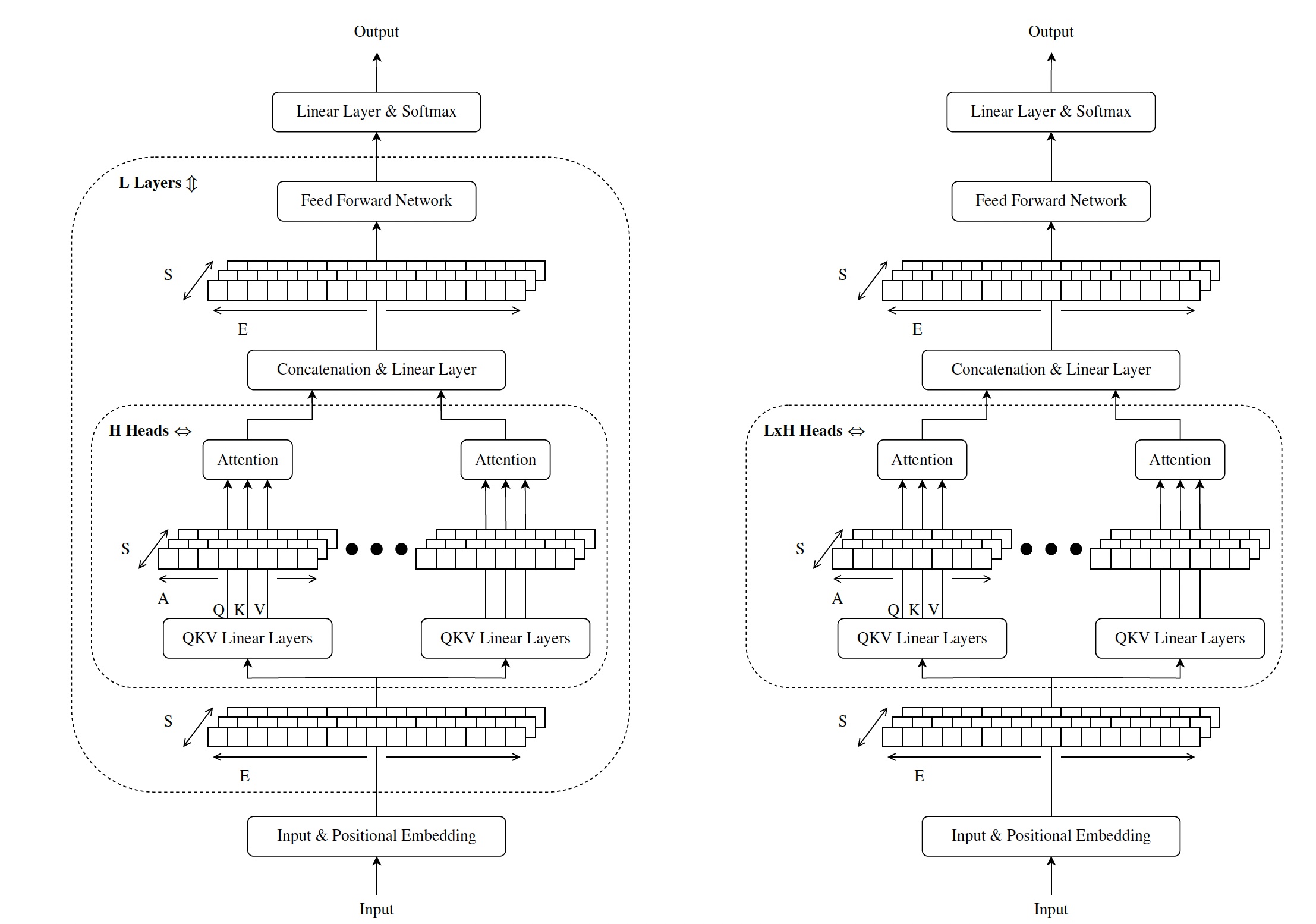
深变压器(左)与宽变压器(右)的比较
像大多数深度学习架构一样,Transformer 模型的学习能力随着它们变得更深而增加。通过将多个注意力层堆叠在一起,您可以使转换器网络能够学习输入空间的更复杂的表示。
然而,添加注意力层的额外好处伴随着一些权衡。首先,它们增加了神经网络的内存占用。其次,它们通过添加更多的串行处理层来增加模型的延迟。第三,它们使模型的可解释性降低,因为随着层数的增加,将输出与特定输入点相关联变得更加困难。
Brown 和他的合著者提出的想法是将深度网络转换为广泛的网络。因此,不是在网络中添加注意力层,而是在注意力层中添加注意力头。这个想法非常简单,但恰好对变压器的性能产生了深远的影响。
例如,考虑一个由六个注意力层组成的转换器模型,每个注意力层有八个注意力头。使用宽网络方法,您可以将架构更改为具有 48 个注意力头的单个注意力层,或具有 24 个注意力头的两个注意力层,或者可能是具有 16 个注意力头的三层。
宽变压器的好处
这种方法有几个好处。首先,虽然 deep 和 Wide Transformer 具有相同数量的注意力头,但 Wide 网络的参数较少,因为它移除了将每个注意力层连接到下一个注意力层的密集层。在至少一种情况下,研究人员能够通过从深架构切换到宽架构,将模型缩小到其原始大小的 48%。其他配置导致内存节省的实质性收益。
第二个好处是速度。由于注意力头并行而不是顺序处理输入,该模型具有更低的延迟和更快的响应。在 CPU 上,研究人员能够将速度提高 3.1 倍,而在 GPU 上,他们获得了 1.9 倍的速度提升。
最后,宽网络比深度转换器更易于解释,因为您可以直接将注意力头特征与输入相关联,而不是通过多个层。“在基于 Transformer 的架构中,可以检查给定输出的注意力机制,以查看每层中每个头的输入特征之间的哪些连接是重要的。对于深度网络,必须对每一层都执行此过程,并且通常会不清楚最终输出实际上是什么,”研究人员写道。“在单层宽网络的情况下,可解释性要容易得多,因为只需要检查一层,并且认为对最终输出重要的内容更加清晰。”
这些改进可以在资源有限且需要实时推理的边缘设备上运行变压器。
还有更多关于宽变压器模型的知识
根据 Brown 和他的合著者的研究结果,从深度变换器切换到宽变换器不仅可以保持性能,而且在某些情况下还可以提高准确性。
“平均而言,更广泛的 Transformer 网络优于深度网络。这一结果既适用于具有点积注意力的“香草”Transformer,也适用于许多其他类型的注意力,”研究人员写道。
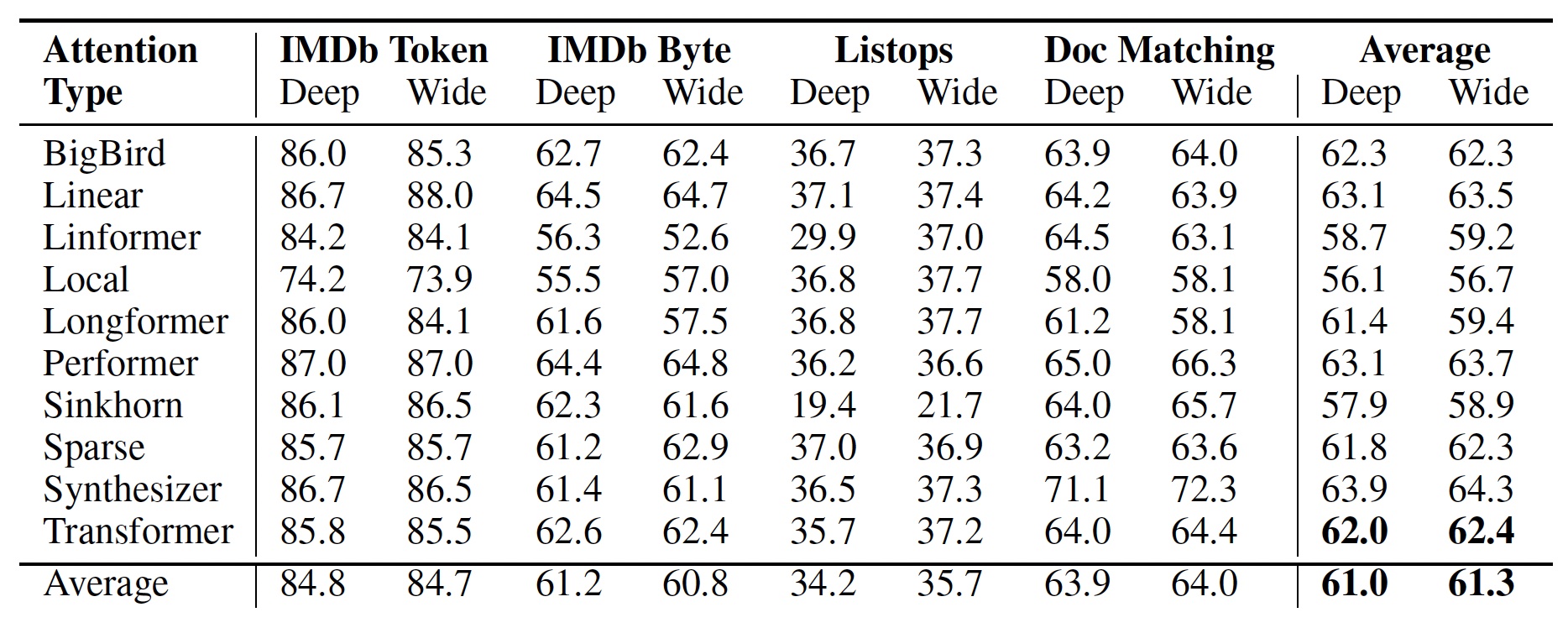
比较深变压器和宽变压器的精度。
然而,到目前为止,这些测试是有限的。作者在四个文本分类任务上测试了广泛的转换器架构。Transformer 有更多的应用,尤其是在语言建模和文本生成方面。测试也仅限于具有六个注意力层和每个注意力头的转换器模型。与 GPT-3 等大型语言模型相比,这是非常有限的,后者有数十个注意力层,每个注意力层都有数十个注意力头和一百多个维度。
但到目前为止,宽变压器模型已被证明是一个非常有前途的研究方向。
“我们想在更大的模型和其他领域(例如语言建模和翻译)上进行测试,但我们时间有限,想发布我们迄今为止的发现,”布朗说。“大型 Transformer 模型,尤其是那些用于 BERT 或 GPT3 等语言建模的模型,由于参数和训练数据数量巨大,从头开始训练非常昂贵。我们希望未来的研究能够探索这些方向,并提高我们对变压器架构的整体理解。”



 微信收款码
微信收款码 支付宝收款码
支付宝收款码